Side Channel Attacks On Linux Kernel
Goal
- Understanding the history of side channel attacks against Linux Kernel.
- Understanding each attacks at high level. (I'll leave some links to get more details)
- Think about the property that all attacks are sharing with.
Bypassing KASLR using Side Channel Attack
-
The first attempt to attack Linux Kernel was introduced by [1] in 2013 as an academic paper.
The authors present different three kinds of side channel attack to defeat KASLR.
But, the approach behind them is exactly same. -
The most important attack in [1] is called "Double Page Fault Attack".
To understand how this attack works, let's see how CPU handles a memory access.- Simple Version
1. [Code] Access to a Virtual Address (VA) 2. [CPU] Translate VA to PA (Physical Address) 3. [CPU] Access to a Physical Address- Deeper Version
1. [Code] Access to a Virtual Address (VA) 2. [CPU] Translate VA to PA (Physical Address) 2-1. [TLB] Perform TLB lookup to find a cache entry for the VA. (TLB - Caching PA associated with VA) 2-2. [Page Table] If 2-1 fails, CPU have to walk page tables to find a corresponding PA. 3. [CPU] Access to a Physical Address -
The insight we can take from "Deeper Version" is that CPU makes a time-difference between 2-1 and 2-2.
Let's imagine the attack scenario for recovering KASLR bits.- Assume that Linux kernel is placed on 0xabc as a virtual address, and TLB already has entries to translate the address, 0xabc.
- If we try to access 0xabc that is the kernel address,
we're able to omit the process 2-2, so the access will be end faster. - If we try to access 0xdbc that is not kernel address, and 0xdbc is invalid memory. (not mapped)
we're not able to omit the process 2-2, page table lookup, so the access will be end slower.
-
One more thing we should keep in our mind
- We act as an user, not the kernel, which means that accessing kernel address leads us to a segmentation fault.
- So we should measure the time duration inside a segmentation fault handler.
- The segmentation fault makes it difficult for an attacker to determine whether addr-a is kernel address.
-
Psuedo Code
int time; unsigned long kaddr = 0xffffffffabc00000; ... void fault_handler(int signo, siginfo_t *info, void *extra) { // 3. measure the time duration between the access violation and here. // If kaddr is correct, the fault will be delivered faster to here. time = get_current_time() - time; ... if (time < threshold) printf("kaddr is kernel address!!\n"); ... } ... int main(int argc, char **argv) { time = get_current_time(); // 1. measure current time. unsigned long d = *kaddr; // 2. access candidate kernel address, // hit access violation that leads us into fault_handler(). } -
Limitation
- This attack suffers from both inaccuracy and slow speed. To understand the reason, turn again our focus to Psuedo Code.
1. [User] Access candidate kernel address. --> Assume it makes time difference about 0.1 ms. (0.1 ~ 0.2 ms) 2. [Kernel] Handling access violation. 3. [Kernel] Deliver the segmentation fault to fault_handler() in user-space. --> 2 and 3 make much bigger time difference, about 10 ms. (5 ~ 15 ms) 4. [User] Measure the time duration. --> Can we make sure that this time difference is made by No.1? - We access an invalid memory, so No.1 takes about 0.2ms. But, Handling access violation in kernel-side luckily takes a short time about 5 ms. That is so fast that we would make a wrong determination.- To overcome this limitation, this attack requires a lot of attempts to increase the probability, making it very slow.
- Then the next question is, How can we overcome this limitation with satisfying both accuracy and speed?
Bypassing KASLR using More Efficient Side Channel Attack
-
How do we built more efficient side channel attack than the first one we've discussed?
The way to do that is to omit the process of handling access violation inside kernel.
Ideally it looks like following.time = get_current_time(); // 1. measure current time. unsigned long d = *kaddr; // 2. access candidate kernel address. --> no jumping to the kernel! time = get_current_time() - time; // 3. measure again. there is no noise for us to measure the time duration. -
How is it possible to be implemented? [2], [3] gives us answers.
-
Breaking Kernel Address Space Layout Randomization with Intel TSX [2]
void TSX_fault_handler(...) { time = get_current_time() - time; // 3. measure again. there is no noise for us to measure the time duration. } int main(...) { time = get_current_time(); // 1. measure current time. unsigned long d = *kaddr; // 2. access candidate kernel address // Directly jump to TSX_fault_handler without interrupt of kernel. // A hardware feature called Intel TSX makes that possible. }- I'll not detail what the TSX is, and how the TSX works. You would easily understand that by simply google:)
-
Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR [3]
time = get_current_time(); // 1. measure current time. prefetch(kaddr); // 2. prefetch candidate kernel address instead of accessing it. time = get_current_time() - time; // 3. measure again. there is no noise for us to measure the time duration.- Prefetch instruction loads a memory to cache. (not commit to register)
It performs TLB and page-table lookup as a load-operation does.
But, It doesn't cause a segmentation fault unlike a normal load-operation.
- Prefetch instruction loads a memory to cache. (not commit to register)
Reading Privileged Memory using Meltdown
- Code gadget
// Run this code in userspace
# rcx : kernel address (== secret)
# rbx : probe array (user data)
# al : least significant byte of rax. secret that attaker wants to know
retry:
(1) mov al, byte [rcx]
(2) shl rax, 0xc
(3) jz retry
(4) mov rbx, qword [rbx + rax]
-
in-order execution (the way a developer expects to work)
- (1) mov al, byte [rcx] --> An access violation occurs. But the value in rcx is stored into al.
- (2) CPU detects the violation, raise an exception.
- (3) Retire (1) --> clobber al (which has a sensitive kernel value)
-
out-of-order execution (the way meltdown expects to work)
- (1) mov al, byte [rcx] --> An access violation occurs. But the value in rcx is stored into al.
- (2) shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax] --> memory-access depending on kernel value(rax) happens prior to raising an exception. - (3) CPU detects the violation at (1), raise an exception, retire (1).
- In this out-of-order exectuion, we could guess the kernel value by examining the memory access happened at (2).
What is the common property of the attacks so far?
-
The attacks we've discussed so far are exploiting one fact,
that is page table of user maps both user and kernel space,
even though a user doesn't need to access kernel-space. -
That can make it possible for a user to try to access kernel memory
even though they can't read/write to the kernel memory. -
What is the way to eliminate the property?
That is eliminating entire kernel mapping from the page tabel a user can see.
How do this close the attacks? -
If the page table doesn't contain kernel mapping,
both access to kernel-memory and access to non-kernel-memory requires a page-table-lookup.
It makes it impossible for an attacker to determine the kernel memory due to no time difference. -
pti image

Attacks exploiting Branch Target Buffer
Branch Prediction
- Modern CPUs have a branch predictor to optimize the performance of branches.
- There are three different kinds of branches that are using Branch Target Buffer (BTB).
// [virtual address]:
0x400: void B(void) {}
void A(int val, void (*fp)(void))
{
0x100: if (val == 1) // 1. Conditional Branch
printf("...");
0x200: B(); // 2. Direct Branch
0x300: fp(); // 3. Indirect Branch
...
}
- Let's look at how the branch prediction works with BTB.
| PC (virtual addr) | Target PC (virtual addr) | Prediction state |
|---|---|---|
| 0x200 | 0x400 | T |
| 0x300 | 0x500 | T |
- In short, BTB stores both the address of branch and the target as a key-value pair.
- BTB's indexing scheme can be different for each architectures.
In Haswell, the low 31 bits are used as a PC. The Target PC records 64-bit full address.
It can allow a BTB collision. For example,
(1) 0x00000011.00002222: jmp 0x00000011.00004444
(2) 0x00000022.00002222: jmp 0x00000022.00004444- (1), (2) have different address. But since they have same low 31 bits for an index of BTB,
BTB would hit a false prediction. - Execute (1) --> Stores "BTB: 00002222 | 0x00000011.00004444"
- Execute (2) --> Uses "BTB: 00002222 | 0x00000011.00004444"
- Execution(2) with BTB results in a false prediction.
- CPU has to detect the false and turn back to original execution.
- Execute (2) --> Store "BTB: 00002222 | 0x00000022.00004444"
- (1), (2) have different address. But since they have same low 31 bits for an index of BTB,
Bypassing KASLR by exploiting Direct Branch (Branch Target Buffer)
-
Jump Over ASLR: Attacking Branch Predictors to Bypass ASLR [5]
-
Even though the side channel attacks using TLB have blocked, we could go another way to acheive the same goal.
The way is to exploit Branch Target Buffer we discussed in the earlier section.

-
The main property we exploit here is that address tag doesn't use the full address as a index of BTB. It makes it possible for us to do aliasing-attack across some boundaries. (user-kernel)
More specifically, since the index contains the KASLR bits, we could bypass KASLR using this primitive. -
Attack scenario
// Kernel address - 0xffffffffabc00000 ==> abc is randomized bits. 1. [User] Allocate memory at 0xabc00000. 2. [User] Perform an direct-branch at 0xabc00000 to other user-memory. - Stores "BTB: 0xabc00000 | user-memory" 3. [User] Perform an direct-branch at 0xabc00000 again. --> It will be fast since it exists in BTB. - Uses "BTB: 0xabc00000 | user-memory" 4. [User] Trigger a syscall 5. [Kernel] Execute a syscall --> If the kernel address is 0xffffffffabc00000, it clears up the BTB entries the user stored. - Stores "BTB: 0xabc00000 | kernel-memory" 6. [User] Perform an direct-branch at 0xabc00000 again. --> Is it slow? then the 0xabc would be correct! - Uses "BTB: 0xabc00000 | kernel-memory" - false prediction! it will be slow!
Reading privileged memory using Branch Target Injection (Direct Branch)
-
"Jump Over ASLR" is an attack to obatin a memory layout information of the kernel.
Let's move one step further. How to read privileged memory with Branch Target Buffer? -
If we can control the BTB entry, we're able to jump to the target we want.
Let's imagine a simple scenario. There are two processes, attacker, victim.
Since BTB is binding to each CPU, we should assume both processes are running under same CPU.// Both processes are running under CPU-0. // Attacker aims to read the memory of victim. // read-gadget: a gadget that opens a side-channel for reading memory. (victim) (0x400) // 1. the way victim works by default 1. [victim] Perform an direct-branch at 0x200 to 0x700. - read-gadget (0x400) is not a target of this branch. // 2. the way victim works under attack 1. [attacker] Allocate memory at 0x200. 2. [attacker] Perform an direct-branch at 0x200 to 0x400. (the address of read-gadget of victim) - Stores "BTB: 0x200 | 0x400" 3. [attacker] Send a command to victim 4. [victim] Perform a direct-branch at 0x200. - Uses "BTB: 0x200 | 0x400" 5. [victim] Jump to 0x400 (read-gadget) due to the false prediction. 6. [victim] Detect the false prediction. Jump to 0x700 again. -
What makes a victim jump to where an attacker wants is called "Branch Target Injection".
One more thing remains. Is it possible to execute whole read-gadget with direct branch prediction? -
Assume that there are two instructions in read-gadget, read-gadget-i1, read-gadget-i2.
CPU handles the jmp instruction with a branch predictor in parallel.
So the race between them might look like below picture.
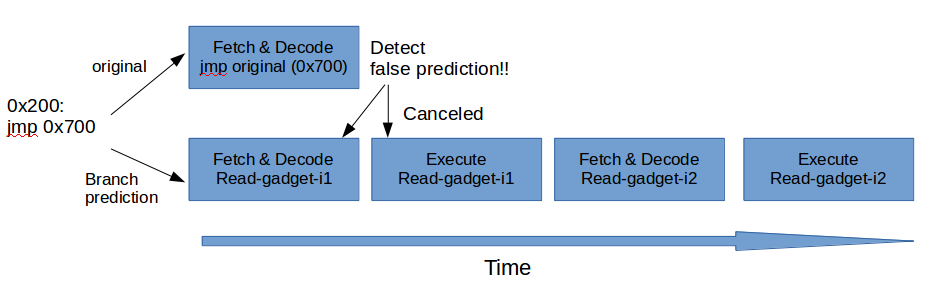
- As shown in the picture, executing whole read-gadget always fails due to the fast detection of false prediction.
next direction? maybe indirect branch!
Reading privileged memory using Branch Target Injection (Indirect Branch, Spectre Variant2)
-
The problem of branch target injecting using direct branch is that the jmp has only one phase,
we should add more phases into the race we saw before to win the race. -
Let's think about phases that an indirect branch contains.
- jmp *(%rax)
- To fix the target of this jmp, (1) Load %rax, (2) Jmp there
- If we can add a latency using (1)Load %rax, we probably win the race.
- jmp *(%rax)
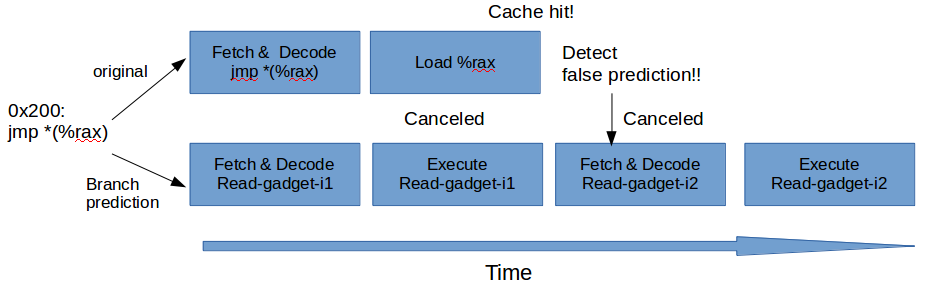
- Let's see above picture. Even though we add Load %rax, we fail to execute all due to the cache hit.
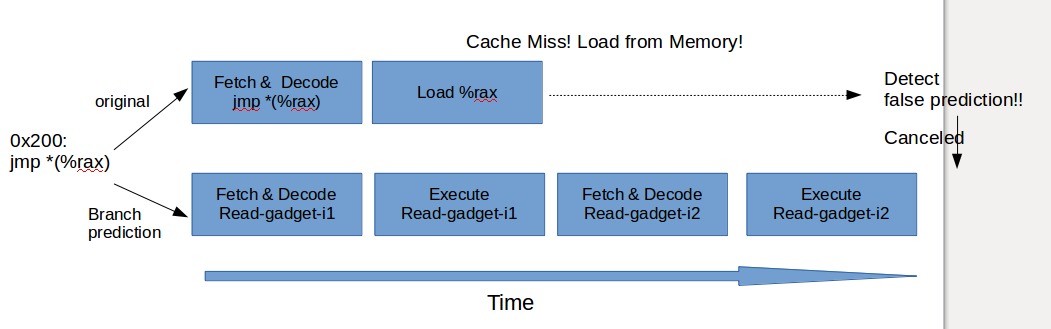
-
If we're able to evict all caches and make sure that cache miss takes place, we would execute whole read gadget! finally get reading privileged memory successfully.
-
In summary, for reading privileged memory, we should leverage both indirect branch and cache eviction. The attack is called Spectre Variant2.
But actually, the exploit in reality is a lot more difficult than you expect because you should take some mitigations like ASLR into account. -
Note some links for you to get more details of how to make a real exploit.
- Spectre-Variant2, Exploiting indirect branches [6] (written in korean, made by myself)
- Reading privileged memory with a side-channel [7] (google project zero)
What is the common property of the BTB attacks?
- BTB doesn't use all parts of the instruction address as an index. It allows BTB to collide across boundaries.
- BTB doesn't have any tagging mechanism to distinguish a number of regions.
It's very important in the view of defense.
Because it means that we're not able to defend them in the same way PTI does unless modifying SoC.
As a result, it opens a new problem that is how to defend them based on software-only approach. - The software-only approach is called Retpoline that aims to eliminate all indirect branches.
- Unfortunately, it's not possible to tag on BTB like below. (because of the lack of hardware support)
| Tag | PC (virtual addr) | Target PC (virtual addr) | Prediction state |
|---|---|---|---|
| Kernel | 0x200 | 0x400 | T |
| Uesr | 0x200 | 0x700 | T |
References
[1] Practical Timing Side Channel Attacks Against Kernel Space ASLR
[2] Breaking Kernel Address Space Layout Randomization with Intel TSX
[3] Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR
[4] Meltdown: Reading Kernel Memory from User Space
[5] Jump Over ASLR: Attacking Branch Predictors to Bypass ASLR
[6] Spectre-Variant2, Exploiting indirect branches
[7] Reading privileged memory with a side-channel
댓글 없음:
댓글 쓰기