Deep dive into Page Table Isolation
Page Table Isolation(PTI)
- It separates a page table of user mode from a page table of kernel mode.
- What attacks can be closed by PTI?
- Bypassing KASLR, Reading kernel memory from userspace (Meltdown)
Concept

- As shown in the above picture, the concept of PTI is to maintain two page tables for one process.
One is for user mode, Another one is for kernel mode.
Challenges
- There are 3 challenges for us to implement PTI in practice.
Challenge-1: How to switch the page table as fast as possible?
- Since we have a different page table for user and kernel,
We should do two more context switches when executing a syscall.
user to kernel, kernel to user.
How can we efficiently implement that?
Challenge-2: Is it possible to eliminate entire kernel mapping?
-
Ideally, Handling a syscall along with the PTI would work as follows.
- Simple Version
1. [User] Trigger a syscall 2. [Kernel] Switch page table to one for the kernel. 3. [Kernel] Handles a syscall -
But if we work with the PTI, it would follow the below process.
- Deeper Version
1. [User - UserMapping] Trigger a syscall 2. [Kernel - UserMapping] Interrupt handling 3. [Kernel - UserMapping] Do something... 4. [Kernel - UserMapping] Switch page table to one for the kernel. 5. [Kernel - KernelMapping] Handles a syscall- What is the problem of the above process?
Even before switch the page table, we need to execute kernel code and data.
But at that point, since page table is still the one for the user, the kernel would crash.
-
That means that we have to figure out what kernel codes and data should be mapped to the page table for a user.
and next, explicitly mapping them to both user-page-table and kernel-page-table.
Challenge-3: How to maintain the TLB efficiently?
- As we discussed earlier, the TLB is a cache for a page table. So we have to synchronize them.
- We must take special care of maintaining the TLB even with separated page table.
- What problem can be occurred if we don't do anything for the TLB?
1. [CPU-0][User] Trigger a syscall 2. [CPU-0][Kernel] Switch page table to one for the kernel. 3. [CPU-0][Kernel] Handles a syscall. --> Loads kernel entires to the TLB of CPU-0. 4. [CPU-0][User] Access a kernel address. - If we access a kernel address, the fault will be delivered faster by the TLB hit due to 3. - If we access an invalid address, the fault will be delivered slower.- It still opens a side channel to an attacker.
- How about explicitly flushing all TLBs in context switching?
1. [CPU-0][User] Trigger a syscall 2. [CPU-0][Kernel] Switch page table to one for the kernel. 3. [CPU-0][Kernel] Handles a syscall. --> Loads kernel entires to the TLB of CPU-0. 4. [CPU-0][Kernel] Flush the TLB of CPU-0. 4. [CPU-0][User] Access a kernel address. - Since the TLB has no entries for kernel address, it perfectly closes a side channel.- It can close a side channel but comes up with a severe performance impact.
- Then, How can we flush the TLB efficiently?
Challenge-1: How to switch the page table as fast as possible?
Concept
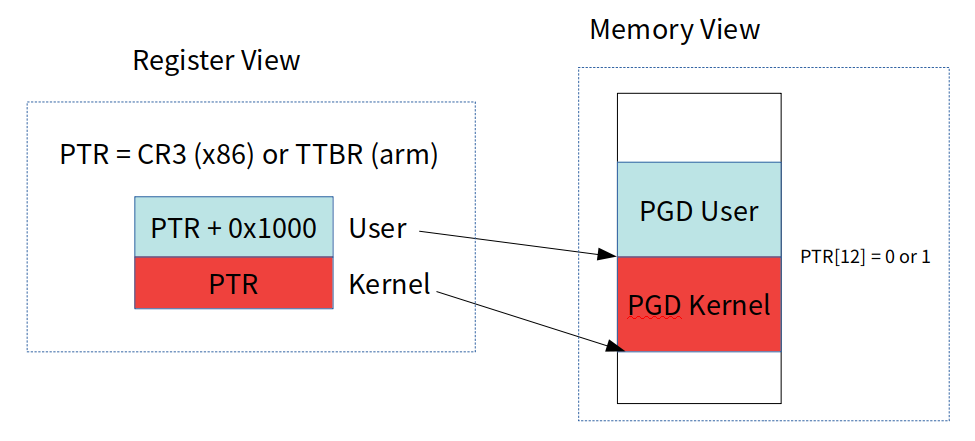
- Very simple concept. The kernel allocates two page tables in adjacent place.
With the layout, we easily can compute the address of the page table switching to.
Implementation on x86_64 (CONFIG_PAGE_TABLE_ISOLATION)
- Allocating two page table.
// arch/x86/include/asm/pgalloc.h
#ifdef CONFIG_PAGE_TABLE_ISOLATION
/*
* Instead of one PGD, we acquire two PGDs. Being order-1, it is
* both 8k in size and 8k-aligned. That lets us just flip bit 12
* in a pointer to swap between the two 4k halves.
*/
#define PGD_ALLOCATION_ORDER 1
#else
#define PGD_ALLOCATION_ORDER 0
#endif
....
....
// arch/x86/mm/pgtable.c
static inline pgd_t *_pgd_alloc(void)
{
return (pgd_t *)__get_free_pages(PGALLOC_GFP, PGD_ALLOCATION_ORDER);
// CONFIG_PAGE_TABLE_ISOLATION --> 8kb, two page tables.
// !CONFIG_PAGE_TABLE_ISOLATION --> 4kb, one page table.
}
- Switching the table.
// arch/x86/include/asm/pgtable.h
#ifdef CONFIG_PAGE_TABLE_ISOLATION
....
....
#define PTI_PGTABLE_SWITCH_BIT PAGE_SHIFT
....
....
static inline pgd_t *kernel_to_user_pgdp(pgd_t *pgdp)
{
return ptr_set_bit(pgdp, PTI_PGTABLE_SWITCH_BIT);
}
static inline pgd_t *user_to_kernel_pgdp(pgd_t *pgdp)
{
return ptr_clear_bit(pgdp, PTI_PGTABLE_SWITCH_BIT);
}
Implementation on arm64 (CONFIG_UNMAP_KERNEL_AT_EL0)
- Allocating two page table.
// [TODO] Where is the code for that? I wasn't able to figure out that..
- Switching the table.
// arch/arm64/kernel/entry.S
#ifdef CONFIG_UNMAP_KERNEL_AT_EL0
/*
* Exception vectors trampoline.
*/
.pushsection ".entry.tramp.text", "ax"
// From User to Kernel
.macro tramp_map_kernel, tmp
mrs \tmp, ttbr1_el1 // Read address of user page table
add \tmp, \tmp, #(PAGE_SIZE + RESERVED_TTBR0_SIZE) // Move it to kernel page table
bic \tmp, \tmp, #USER_ASID_FLAG // For the TLB
msr ttbr1_el1, \tmp // Write address of kernel page table to register
....
....
// From Kernel to User
.macro tramp_unmap_kernel, tmp
mrs \tmp, ttbr1_el1
sub \tmp, \tmp, #(PAGE_SIZE + RESERVED_TTBR0_SIZE)
orr \tmp, \tmp, #USER_ASID_FLAG
msr ttbr1_el1, \tmp
Challenge-2: Is it possible to eliminate entire kernel mapping?
Concept
- Our goal is to minimize the amount of kernel mapping allowed to user page table. Which can reduce the amount of attack surfaces.
- There might be two approaches.
Approach-1 : trampoline replacing exception entry (on arm64)
- Install a trampoline code replacing original exception entry. When syscall hits, execution will first fall down to the trampoline.
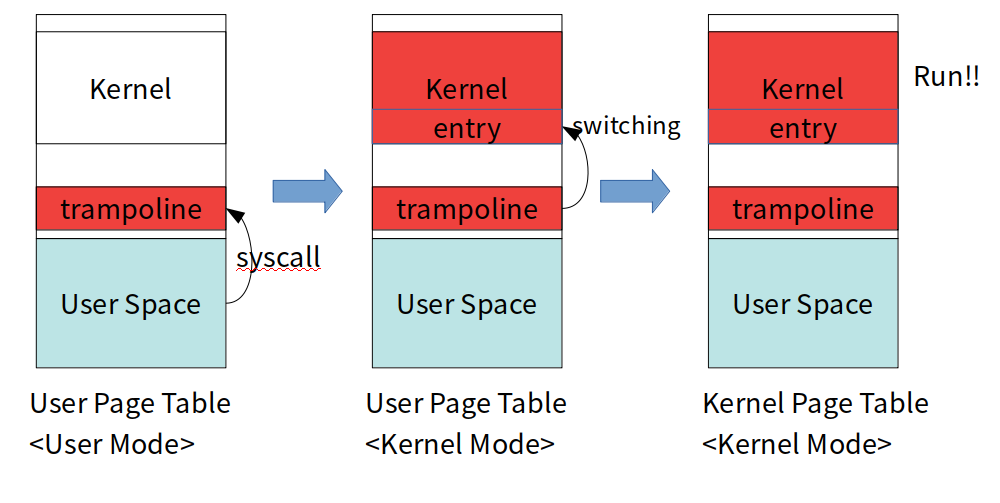
-
Strengths
- What an attacker gain by side channel attacks (on KASLR, Meltdown) is limited to about the trampoline.
-
Weaknesses
- An indirect jump to original entry is additionally needed. (bad performance in the view of leveraging cache)
Direct jump on full 64-bit may not be supported on any vendors, and even if it's possible, it indirectly exposes the address of kernel entry.
- An indirect jump to original entry is additionally needed. (bad performance in the view of leveraging cache)
-
arm64 is taking this approach, x86_64 is not taking this approach.
Approach-2 : no trampoline. allowing a minimum set of mapping. (percpu on x86)
- Allow user page table to map a minimum set of codes required before switching page table.

-
Strengths
- No indirect branch (good performance)
-
Weaknesses
- Allows side channel attacks to locate percpu area. (they said it's ok since it doesn't directly leak KASLR. (really??))
Implementation on arm64 (CONFIG_UNMAP_KERNEL_AT_EL0)
- Define section for trampoline
// arch/arm64/kernel/vmlinux.lds.S
#ifdef CONFIG_UNMAP_KERNEL_AT_EL0
#define TRAMP_TEXT \
. = ALIGN(PAGE_SIZE); \
__entry_tramp_text_start = .; \
*(.entry.tramp.text) \
. = ALIGN(PAGE_SIZE); \
__entry_tramp_text_end = .;
#else
#define TRAMP_TEXT
#endif
- From trampoline to original exception vector
// arch/arm64/kernel/entry.S
// trampoline for pti
ENTRY(tramp_vectors)
.space 0x400
tramp_ventry
tramp_ventry
tramp_ventry
tramp_ventry
tramp_ventry 32
tramp_ventry 32
tramp_ventry 32
tramp_ventry 32
END(tramp_vectors)
....
....
.macro tramp_ventry, regsize = 64
.align 7
...
tramp_map_kernel x30 // Switch page table
#ifdef CONFIG_RANDOMIZE_BASE
adr x30, tramp_vectors + PAGE_SIZE // Get the address of original exception vector
alternative_insn isb, nop, ARM64_WORKAROUND_QCOM_FALKOR_E1003
ldr x30, [x30]
#else
ldr x30, =vectors
#endif
...
add x30, x30, #(1b - tramp_vectors)
isb
ret // Jump to the original exception vector
.endm
....
/*
* Exception vectors.
*/
.pushsection ".entry.text", "ax"
.align 11
ENTRY(vectors)
...
kernel_ventry 0, sync // Synchronous 64-bit EL0 --> handles a syscall
- Map trampoline to user page table
#ifdef CONFIG_UNMAP_KERNEL_AT_EL0
static int __init map_entry_trampoline(void)
{
pgprot_t prot = rodata_enabled ? PAGE_KERNEL_ROX : PAGE_KERNEL_EXEC;
phys_addr_t pa_start = __pa_symbol(__entry_tramp_text_start);
/* The trampoline is always mapped and can therefore be global */
pgprot_val(prot) &= ~PTE_NG; // ~PTE_NG!!
/* Map only the text into the trampoline page table */
memset(tramp_pg_dir, 0, PGD_SIZE);
__create_pgd_mapping(tramp_pg_dir, pa_start, TRAMP_VALIAS, PAGE_SIZE,
prot, __pgd_pgtable_alloc, 0);
Implementation on x86_64 (CONFIG_PAGE_TABLE_ISOLATION)
- Map percpu area to user page table
static void __init setup_cpu_entry_area(unsigned int cpu)
{
....
....
cea_set_pte(&cea->gdt, get_cpu_gdt_paddr(cpu), gdt_prot);
cea_map_percpu_pages(&cea->entry_stack_page,
per_cpu_ptr(&entry_stack_storage, cpu), 1,
PAGE_KERNEL);
....
cea_map_percpu_pages(&cea->tss, &per_cpu(cpu_tss_rw, cpu),
sizeof(struct tss_struct) / PAGE_SIZE, tss_prot);
}
....
....
void cea_set_pte(void *cea_vaddr, phys_addr_t pa, pgprot_t flags)
{
unsigned long va = (unsigned long) cea_vaddr;
pte_t pte = pfn_pte(pa >> PAGE_SHIFT, flags);
/*
* The cpu_entry_area is shared between the user and kernel
* page tables. All of its ptes can safely be global.
* _PAGE_GLOBAL gets reused to help indicate PROT_NONE for
* non-present PTEs, so be careful not to set it in that
* case to avoid confusion.
*/
if (boot_cpu_has(X86_FEATURE_PGE) &&
(pgprot_val(flags) & _PAGE_PRESENT))
pte = pte_set_flags(pte, _PAGE_GLOBAL); // _PAGE_GLOBAL!!
- Swithing the table at syscall entry
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
/*
* Interrupts are off on entry.
* We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON,
* it is too small to ever cause noticeable irq latency.
*/
swapgs
/* tss.sp2 is scratch space. */
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2) // percpu-access before switching. since user already maps percpu area, it would be ok.
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp // Swithing the table
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
Challenge-3: How to maintain the TLB efficiently?
Concept
- Uses implicitly TLB flush.
- We can assign the different tag to a TLB entry so that it's not needed anymore to explicitly do the TLB flush.
It's the typical way used in maintaining TLBs for different processes.
It works by hardware features called PCID(x86) and ASID(arm).
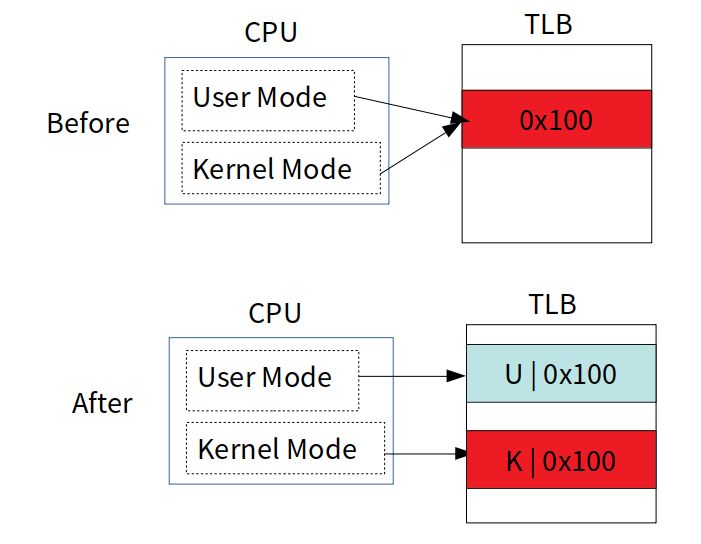
Implementation on x86_64 (CONFIG_PAGE_TABLE_ISOLATION)
- Assigning rule
// arch/x86/entry/calling.h
/*
* The x86 feature is called PCID (Process Context IDentifier).
....
* ASID - [0, TLB_NR_DYN_ASIDS-1]
* the canonical identifier for an mm
*
* kPCID - [1, TLB_NR_DYN_ASIDS]
* the value we write into the PCID part of CR3; corresponds to the
* ASID+1, because PCID 0 is special.
*
* uPCID - [2048 + 1, 2048 + TLB_NR_DYN_ASIDS]
* for KPTI each mm has two address spaces and thus needs two
* PCID values, but we can still do with a single ASID denomination
* for each mm. Corresponds to kPCID + 2048.
*
// For instance, assume a process-p.
// process-p - ASID: 10 / kPCID : 10+1 / uPCID : 10+1+2048
// ASID acts as a placeholder here, kPCID is for kernel entry of process-p, uPCID is for user entry of process-p.
- Tagging
#define PTI_USER_PGTABLE_AND_PCID_MASK (PTI_USER_PCID_MASK | PTI_USER_PGTABLE_MASK)
.macro ADJUST_KERNEL_CR3 reg:req
ALTERNATIVE "", "SET_NOFLUSH_BIT \reg", X86_FEATURE_PCID
/* Clear PCID and "PAGE_TABLE_ISOLATION bit", point CR3 at kernel pagetables: */
andq $(~PTI_USER_PGTABLE_AND_PCID_MASK), \reg // we just need to flip one bit!
.endm
.macro SWITCH_TO_KERNEL_CR3 scratch_reg:req
ALTERNATIVE "jmp .Lend_\@", "", X86_FEATURE_PTI
mov %cr3, \scratch_reg
ADJUST_KERNEL_CR3 \scratch_reg // tagging to cr3 register. low 12bits of cr3 is used to specify PCID.
mov \scratch_reg, %cr3
.Lend_\@:
.endm
Implementation on arm64 (CONFIG_UNMAP_KERNEL_AT_EL0)
- Tagging
#define USER_ASID_BIT 48 // ARM stores ASID (for TLB-tagging) in high 16bits of TTBR register.
#define USER_ASID_FLAG (UL(1) << USER_ASID_BIT)
#define TTBR_ASID_MASK (UL(0xffff) << 48)
.macro tramp_map_kernel, tmp
mrs \tmp, ttbr1_el1
add \tmp, \tmp, #(PAGE_SIZE + RESERVED_TTBR0_SIZE)
bic \tmp, \tmp, #USER_ASID_FLAG // tagging to TTBR1_EL1 register.
msr ttbr1_el1, \tmp
- Assigning rule
// bit[48] is reserved for indicating kernel or user.
// so if CONFIG_UNMAP_KERNEL_AT_EL0 is enabled, we have to shift 1bit in computing original ASID.
#ifdef CONFIG_UNMAP_KERNEL_AT_EL0
#define NUM_USER_ASIDS (ASID_FIRST_VERSION >> 1)
#define asid2idx(asid) (((asid) & ~ASID_MASK) >> 1)
#define idx2asid(idx) (((idx) << 1) & ~ASID_MASK)
#else
#define NUM_USER_ASIDS (ASID_FIRST_VERSION)
#define asid2idx(asid) ((asid) & ~ASID_MASK)
#define idx2asid(idx) asid2idx(idx)
#endif
References
[1] arm64 pti patch
[2] x86 pti patch
[3] x86/pti/64: Remove the SYSCALL64 entry trampoline
댓글 없음:
댓글 쓰기