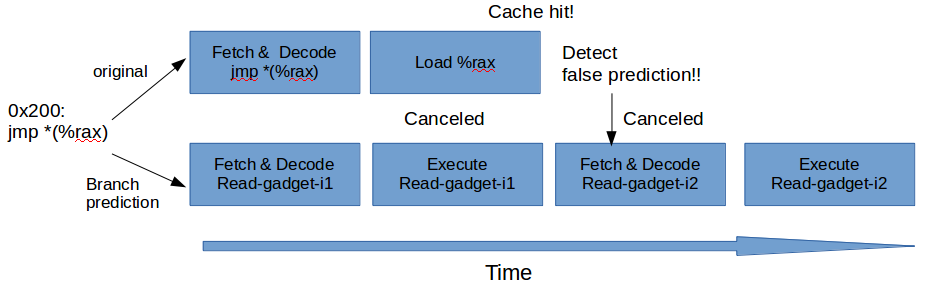
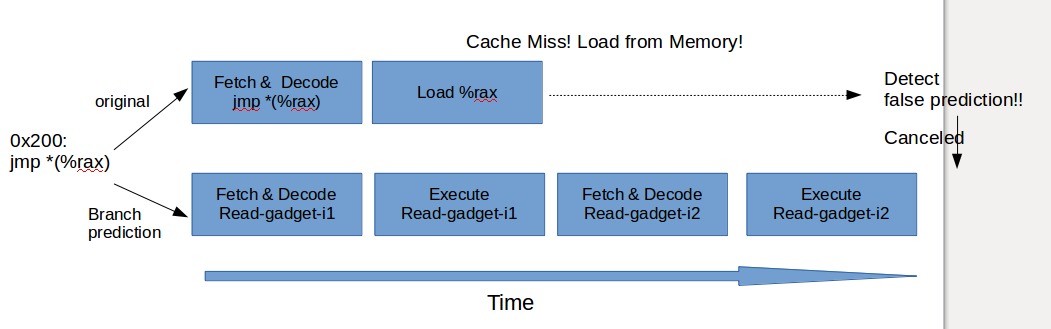
Deep dive into Defense against BTB attacks (Branch Target Buffer)
Briefs on BTB attacks
-
Branch Target Collision
- Can: Obtain the layout information (ASLR, KASLR)
- Can't: Read the privileged memory
-
Branch Target Injection
- Can: Read the privileged memory
Briefs on BTB defenses
-
Retpoline [1]
- Blocks both Branch Target Collision and Branch Target Injection.
- Prevents all exploits based on branch target buffer
- Arch: x86, amd (Linux distros)
-
Flush BTB entries explicitly [2]
- Blocks Branch Target Injection only. (How to deal with Branch Target Collision? ignore it? do they have another solution?)
- Note: Actually it has been deprecated in latest kernel.
- Arch: arm
Flush BTB entries explicitly
- The simplest way to stop to leak KASLR bits (Branch Target Collision),
is to perform the BTB flush in switching context between user and kernel.
- Likewise, the way to stop Branch Target Injection
is to perform the BTB flush in switching context between processes, VMs.
- ARM takes this approach, because easy to implement, no side effects.
there are 3 spots to flush the BTB entries.
(But in latest kernel, It seems be deprecated.)- (1) Context Switch Between User and Kernel
- It stops to leak KASLR bits, but at the same time, imposes a severe performance overhead.
- (2) Context Switch Between User Processes
- It stops Branch Target Injection between User Processes. (no memory leak of a victim process)
- (3) Context Switch Between VMs
- It stops Branch Target Injection between VMs. (no memory leak of VM, Host)
- It stops Branch Target Injection between VMs. (no memory leak of VM, Host)
- (1) Context Switch Between User and Kernel
- ARM has adopted both (2) and (3) in its Linux Kernel.
(1) has not adopted because of the performance impact in it.
[TODO] But.. does this decision mean ARM allows KASLR-leak??
- ARM doesn't flush all BTB entries. Instead, they partially flush BTB entries that are exploitable to Branch Target Injection.
and ARM's hardening is also depending on CPU type. It means they don't do anything on the CPU not vulnerable to Branch Target Injection.
- In summary, ARM determines where the BTB flush performs in considering
- CPU Type
- If a CPU is not fundamentally vulnerable to BTB attacks, There are no BTB flushes.
- Interest of an attacker
- Even if a CPU is vulnerable, ARM doesn't do the flush on all three spots. (1), (2), (3).
- Identify some spots where attackers are interested in,
and do the BTB flush on the spots. That significantly reduces a number of BTB flushes. - ARM provides an interface for a developer to add a new spot for BTB flush.
- CPU Type
- In latest linux kernel (v5.2), There seems no BTB flushes anywhere.
I think ARM thinks of the BTB flush as a temporal fix.
- ARM takes special care of KVM vector, EL2 vector. ARM replaces the original vectors with hardened vectors instead of performing the BTB flush.
- Linux kernel code (CONFIG_HARDEN_BRANCH_PREDICTOR, ARM64_HARDEN_BRANCH_PREDICTOR)
// Code-1: KVM
// Assumption behind it: An attacker can inject a branch target across VMs through a hyp-vector.
// Strategy: Makes sure that no branch prediction happens in hardened vector.
// [TODO] I don't understand it clearly. (Does NOPs work for no branch prediction?)
#ifdef CONFIG_HARDEN_BRANCH_PREDICTOR
....
// the hardening sequence is placed in one of the kvm vector slots.
static inline void *kvm_get_hyp_vector(void)
{
....
if (cpus_have_const_cap(ARM64_HARDEN_BRANCH_PREDICTOR) && data->fn) {
vect = kern_hyp_va(kvm_ksym_ref(__bp_harden_hyp_vecs_start));
slot = data->hyp_vectors_slot;
}
....
return vect;
}
....
ENTRY(__kvm_hyp_vector) // original hyp vector
....
valid_vect el1_sync // Synchronous 64-bit EL1
....
ENDPROC(__kvm_hyp_vector)
.macro hyp_ventry
.align 7
1: .rept 27
nop
.endr
....
* Where addr = kern_hyp_va(__kvm_hyp_vector) + vector-offset + 4.
* See kvm_patch_vector_branch for details.
*/
alternative_cb kvm_patch_vector_branch
b __kvm_hyp_vector + (1b - 0b)
....
alternative_cb_end
.endm
.macro generate_vectors
0:
.rept 16
hyp_ventry
.endr
.org 0b + SZ_2K // Safety measure
.endm
.align 11
ENTRY(__bp_harden_hyp_vecs_start) // hardened vector
.rept BP_HARDEN_EL2_SLOTS
generate_vectors
.endr
ENTRY(__bp_harden_hyp_vecs_end)
// Code-2: Switching context between processes
static u64 new_context(struct mm_struct *mm)
{
...
//
switch_mm_fastpath:
arm64_apply_bp_hardening();
// It means partially invalidating BTB. But, nothing happens in latest kernel.
// Code-3: Instruction abort that user triggers (Prefetch abort)
asmlinkage void __exception do_el0_ia_bp_hardening(unsigned long addr, ...
{
....
if (!is_ttbr0_addr(addr))
arm64_apply_bp_hardening();
// It means partially invalidating BTB. But, nothing happens in latest kernel.
Retpoline
- Retpoline works by replacing all indirect jumps with direct jumps.
It relies on the fact that the attacks are infeasible if there are no indirect jumps.
And Retpoline makes a gadget that has no point at which speculation could be controlled by an external attacker.
Indirect jump replacement with retpoline
- Before retpoline
jmp *%rax
- After retpoline
(1) call load_label
capture_ret_spec:
(2) pause; LFENCE
(3) jmp capture_ret_spec
load_label:
(4) mov %rax, (%rsp)
(5) ret
-
Our goal is to jump to where the value in rax is pointing.
-
(1) --> (4) --> (5). That sequences means we're using ret instruction to jump to somewhere.
But, it opens a new side channel that is RSB. (Return Stack Buffer)
So we should also take special care of RSB. -
(5) ret triggers a new speculative execution relying on RSB.
If speculating, the CPU uses the RSB entry created in (1) and jumps to (2). -
(2) uses a barrier and (3) jumps to (2) again. What do they mean?
To make sure no speculation on (5), %rax must be taken from the stack memory.
If there is no barrier, and hit (5) again, the speculating happens again at (5).
That's why (2) is needed. -
When (2) finishes, the CPU can execute either (3) or (5).
If (3) is not there, the speculating happens again at (5).
That's why (3) is needed.
-
Return Stack Buffer (RSB)
- N entries that store recent return addresses.
- When hitting call instruction, push the corresponding return address into RSB.
- When hitting ret instruction, pop off the return address from RSB.
- RSB: | ret-1 | ret-2 | ret-3 | ....
- In above retpoline gadget, if (5) consumes the corresponding RSB and hit (5) in the context of speculation, (5) jumps to an undesired target.
-
Do LFENCE and PAUSE impose a lot of performance overhead?
- If a CPU always executes the LFENCE, the answer is yes.
But the LFENCE would be executed in context of speculative execution.
Since benign execution will not trigger the LFENCE, it may not exhibit the same performance impact typically associated with speculation barriers.
- If a CPU always executes the LFENCE, the answer is yes.
-
For details about replacing call instruction, check out [3].
How Linux kernel supports Retpoline
-
There are 3 options about the way how Linux kernel supports Retpoline.
- retpoline : replace indirect branches
- retpoline,generic : google's original retpoline (This is what we've looked at in the previous section)
- retpoline,amd : AMD-specific minimal thunk
-
Linux kernel mainline uses "retpoline" by default. (for x86_64_defconfig)
Ubuntu kernel uses "retpoline,generic" by default. (It means a full retpoline protection) -
Let's look at the "retpoline" that Linux kernel mainline adopts. (CONFIG_RETPOLINE)
- "retpoline" version applies two different retpoline gadgets based on the severity of some codes.
- Default Gadget (used everywhere except BPF JIT)
- Default Gadget doesn't provide a perfect protection. Instead, add some hardening.
Since all normal BTB updates are running in _x86_indirect_thunk[r], it's difficult for an attacker to mistrain that. - This approach reduces performance overhead coming up with full retpoline protection.
// kernel code # define CALL_NOSPEC \ ANNOTATE_NOSPEC_ALTERNATIVE \ ALTERNATIVE_2( \ ANNOTATE_RETPOLINE_SAFE \ "call *%[thunk_target]\n", \ "call __x86_indirect_thunk_%V[thunk_target]\n", \ X86_FEATURE_RETPOLINE, \ "lfence;\n" \ ANNOTATE_RETPOLINE_SAFE \ "call *%[thunk_target]\n", \ X86_FEATURE_RETPOLINE_AMD) # define THUNK_TARGET(addr) [thunk_target] "r" (addr) // kernel binary dump // Before retpoline: jmpq *%rbx; callq ffffffff81e00f20 <__x86_indirect_thunk_rbx> .... // All indirect branches through rbx are here. // Even though an attacker mistrain this branch, // Other dummy calls (view of attacker) will wipe the malicious entry out from BTB. // So it makes an effective hardening with a reasonable performance impact. ffffffff81e00f20 <__x86_indirect_thunk_rbx>: ffffffff81e00f20: ff e3 jmpq *%rbx ffffffff81e00f22: 90 nop ffffffff81e00f23: 90 nop .... ffffffff81e00f40 <__x86_indirect_thunk_rcx>: ffffffff81e00f40: ff e1 jmpq *%rcx ffffffff81e00f42: 90 nop ffffffff81e00f43: 90 nop ffffffff81e00f44: 90 nop - Default Gadget doesn't provide a perfect protection. Instead, add some hardening.
- BPF JIT Gadget (only used in BPF JIT)
- Even if default gadgets are adopted in entire kernel code,
attacker could generate some codes where the speculation could be executed via BPF JIT. - So we should apply full retpoline protection to a code generation logic of BPF JIT.
// kernel code #ifdef CONFIG_RETPOLINE # ifdef CONFIG_X86_64 # define RETPOLINE_RAX_BPF_JIT_SIZE 17 # define RETPOLINE_RAX_BPF_JIT() \ do { \ EMIT1_off32(0xE8, 7); /* callq do_rop */ \ /* spec_trap: */ \ EMIT2(0xF3, 0x90); /* pause */ \ EMIT3(0x0F, 0xAE, 0xE8); /* lfence */ \ EMIT2(0xEB, 0xF9); /* jmp spec_trap */ \ /* do_rop: */ \ EMIT4(0x48, 0x89, 0x04, 0x24); /* mov %rax,(%rsp) */ \ EMIT1(0xC3); /* retq */ \ } while (0) // kernel code - arch/x86/net/bpf_jit_comp.c static void emit_bpf_tail_call(u8 **pprog) { .... /* * Wow we're ready to jump into next BPF program * rdi == ctx (1st arg) * rax == prog->bpf_func + prologue_size */ RETPOLINE_RAX_BPF_JIT(); .... - Even if default gadgets are adopted in entire kernel code,
- "retpoline" version applies two different retpoline gadgets based on the severity of some codes.
-
Next look at the "retpoline,generic" that Ubuntu kernel adopts. (full retpoline protection)
- "retpoline,generic" uses only one retpoline gadget that google introduced.
// kernel code .macro RETPOLINE_JMP reg:req call .Ldo_rop_\@ .Lspec_trap_\@: pause lfence jmp .Lspec_trap_\@ .Ldo_rop_\@: mov \reg, (%_ASM_SP) ret .endm /* * This is a wrapper around RETPOLINE_JMP so the called function in reg * returns to the instruction after the macro. */ .macro RETPOLINE_CALL reg:req jmp .Ldo_call_\@ .Ldo_retpoline_jmp_\@: RETPOLINE_JMP \reg .Ldo_call_\@: call .Ldo_retpoline_jmp_\@ .endm // kernel binary // there are no callers using this retpoline gadget in binary // Instead record all sites that should be rearranged to a retpoline gadget. // __alt_instructions ~ __alt_instructions_end; ffffffff828d17df <.altinstr_replacement>: .... // indirect call using %rdi ffffffff828d17ee: e8 07 00 00 00 callq 0xffffffff828d17fa ffffffff828d17f3: f3 90 pause ffffffff828d17f5: 0f ae e8 lfence ffffffff828d17f8: eb f9 jmp 0xffffffff828d17f3 ffffffff828d17fa: 48 89 3c 24 mov %rdi,(%rsp) ffffffff828d17fe: c3 retq .... // indirect call using %rbx ffffffff828d1831: e8 07 00 00 00 callq 0xffffffff828d183d ffffffff828d1836: f3 90 pause ffffffff828d1838: 0f ae e8 lfence ffffffff828d183b: eb f9 jmp 0xffffffff828d1836 ffffffff828d183d: 48 89 1c 24 mov %rbx,(%rsp) ffffffff828d1841: c3 retq // kernel runtime // runtime patching to apply retpoline gadgets apply_alternatives(__alt_instructions, __alt_instructions_end); // Strengths // - Enable/Disable Retpoline in boot-time // - For disable Retpoline in boot-time, using "spectre_v2=off" on kernel command line.
- "retpoline,generic" uses only one retpoline gadget that google introduced.
Why can't ARM use Retpoline?
-
This is a quite interesting question.
ARM didn't say anything about that in their whitepaper [4].
I can't know the exact reason for that. The only thing I can do is just guessing. -
x86's direct call instruction works in two phases.
- push return address into stack
- jump to dest
-
Likewise x86's return instruction works in two phases.
- pop off return address from stack
- jump to address
-
arm's direct call instruction(bl) works in one phase.
- mov lr, =next instruction(pc)
- mov pc, =dest
-
Likewise arm's return instruction works in one phase.
- mov pc, lr (no acceess to stack)
-
As shown in the above, ARM doesn't push the return address into the stack in branching.
It means that it's so difficult to handle speculation on both RSB and BTB.
(I think, in particular, making no speculation on RSB would be difficult.)
Appendix
Appendix-1: The flow of handling hvc in KVM
- [Guest Kernel] Issue hvc (or trap)
- [Guest Kernel] Load kvm vector & Jump to vector entry
- [Hypervisor] Do __guest_exit. exit from guest, enter to host to handle the hvc. (__kvm_hyp_vector)
- [Host Kernel] Handling the hvc (or trap)
- [Host Kernel] Do __guest_enter. exit from host, enter to guest.
- [Guest Kernel] Do next instruction to hvc (or trap)
References
[1] Retpoline: a software construct for preventing branch-target-injection
[2] arm64 kpti hardening and variant 2 workarounds
[3] Deep Dive: Retpoline: A Branch Target Injection Mitigation
[4] ARM - Cache Speculation Issues Update